I've flirted with the idea of doing this on and off for years now, but this evening I've decided I'm going to focus on a microcode-level 68000 emulation core, and I'm going to continue with it until it's a reality. The sheer amount of data and work involved in this space feels a bit overwhelming right now though, and I need your help. My goal right now is to better understand the way the 68000 operates internally, especially how exactly the CPU takes opcodes, and translates those to microcode/nanocode instructions, what those instructions are, and what specific internal operations they perform when they execute. I'm planning to immerse myself in this until I "get it" and ask questions here, but first of all I want to make sure I'm working with the best information to hand. I'm currently trying to pull together all the best resources in this area, and here's the list I've compiled so far:
https://og.kervella.org/m68k - Oliver Galibert's incredible work on a schematic and microcode/nanocode transcription and analysis from the 68000 decap
viewtopic.php?f=2&t=2925 - Flamewing's fantastic research and listing of relevant patents for the 68000
viewtopic.php?p=32693#p32693 - Flamewing's example of turning microcode data in patent into series of actual steps in plain English
viewtopic.php?p=30943#p30943 - Flamewing's microcode analysis of ABCD and SBCD opcodes
viewtopic.php?f=2&t=2962 - Gigasoft's great analysis on the physical layout and execution stages of the 68000 die from Oliver's schematic
EDIT: More references -
viewtopic.php?p=33999#p33999 - Flamewing giving a detailed breakdown of btst microcode
https://github.com/ijor/fx68k - ijor's verilog implementation of the 68000 based on decap. Has many of the internal control lines from the nanocode output identified in particular.
Although I know the 68000 itself very well from an external programmer's perspective, internally it's a whole different beast, and I'm coming into this as a total beginner. Any help finding my feet is very much appreciated. Does anyone have any other resources they'd point to, or any other handy information, advice, or general encouragement to offer? Also, is there anyone else here who's made a serious attempt at this that would like to offer advice or compare/share notes? I'd love to be able to work on something like this collaboratively if anyone else is working in this space.
I'm officially building a microcode-level 68000 core
Moderator: BigEvilCorporation
I'm officially building a microcode-level 68000 core
Last edited by Nemesis on Mon May 06, 2019 12:10 am, edited 1 time in total.
Re: I'm officially building a microcode-level 68000 core
Does anyone here know how to get in touch with Olivier Galibert? I've found he's put together... something at https://github.com/galibert/m68ksim, but there's no comments, no readme, no documentation of any kind, and apparently no reference to it anywhere on the internet. There's also a bit of a fondness for abbreviated variable and function names. Can anyone decipher what this means?
Yeah, me neither.
Code: Select all
bool n2388 = !(s.clk || s.berro || s.n1361 || s.n2735 || s.n2772 || s.n2781);-
Chilly Willy
- Very interested
- Posts: 2984
- Joined: Fri Aug 17, 2007 9:33 pm
Re: I'm officially building a microcode-level 68000 core
From the other repos on his github account, I'd say it's all tool generated, so don't expect most of it to mean anything at all. The more important parts seem somewhat obvious - eu is execution unit, berro is probably bus error output, etc.
Re: I'm officially building a microcode-level 68000 core
Tool generated would certainly explain why it's so incomprehensible, thanks for taking a look.
-
TmEE co.(TM)
- Very interested
- Posts: 2443
- Joined: Tue Dec 05, 2006 1:37 pm
- Location: Estonia, Rapla City
- Contact:
Re: I'm officially building a microcode-level 68000 core
These names make me think of stuff seen in Visual6502
Mida sa loed ? Nagunii aru ei saa 
http://www.tmeeco.eu
Files of all broken links and images of mine are found here : http://www.tmeeco.eu/FileDen
http://www.tmeeco.eu
Files of all broken links and images of mine are found here : http://www.tmeeco.eu/FileDen
Re: I'm officially building a microcode-level 68000 core
I'm currently working on understanding the information that's in the patents, specifically US4325121. A lot of important information is contained in the microword descriptions in Appendix H, but they're borderline illegible, and very difficult to work with in their current form, so I'm doing a full transcription to make it searchable and easier to read. Here's an example of the result:
There are 92 pages, and I've currently fully completed the first 28, with the rest partially complete. I'll chip away at it over the coming days. One thing that's nice after transcribing it is it's easy to restore into the original large "sheets" the information was drawn from. Here are sheets "A" and "B" in this format:
http://nemesis.exodusemulator.com/M6800 ... heet A.pdf
http://nemesis.exodusemulator.com/M6800 ... heet B.pdf
I'll post the full transcription when it's done.
Code: Select all
##########################################################################################################################
Appendix H - Page 12(96) - FIG. 13L
##########################################################################################################################
SHEET B 0 1 2
____________________________________ ____________________________________ ____________________________________
| | | | < | | | <> | |
| au --> pc | np | | au --> db --> aob,au,pc | irix | | alu --> db --> ath | trim |
| (dbin) --> dbd --> alub |--------| | (dbin) --> ab --> alu,rxl |--------| | (alub) --> alu |--------|
| (rxd) --> ab* --> dcr | db | | -1 --> alu | dbi | | au --> aob,pc | db |
| (rya) --> db --> au |--------| | +2 --> au |--------| | (dbin) --> ab --> atl |--------|
A | -1,-2 --> au | x | | | 1if | | edb --> dbin | 1n |
| |--------| | |--------| | -1 --> alu |--------|
| | rxry | | | rxuk | | | dxuk |
|___________________________|________| |___________________________|________| |___________________________|________|
| 3c4 | asxw1 | pdcw1 | | a6 | mrgl1 | mrgw1 | | 2b5 | mall1 | mall1 |
\------------------------------------/ \------------------------------------/ \------------------------------------/
| | |
v v v
____________________________________ ____________________________________ ____________________________________
| < m | | | > | | | <> | |
| au --> * --> aob,rya | irop | | (alub) --> alu | frix | | alu --> dob | twop |
| (dbin) --> ab* --> alu |--------| | (alue) --> db --> rxh |--------| | (ath) --> dbh --> aob,au |--------|
| -1 --> alu | db | | edb --> dbin,irc | a1 | | (atl) --> ab --> alu | db |
| |--------| | (ir) --> ird |--------| | (dbin) --> dbl --> aob,au |--------|
B | | 1n | | -1 --> alu | 1f | | -1 --> alu | 1i |
| |--------| | |--------| | +2 --> au |--------|
| | | | | | | | |
|___________________________|________| |___________________________|________| |___________________________|________|
| 100 | asxw2 | asxw2 | | 66 | mrgl2 | mrgl2 | | 2b6 | mall2 | mall2 |
\------------------------------------/ \------------------------------------/ \------------------------------------/
| |
v v
____________________________________ ____________________________________
| > m | | | <> | |
| edb --> dbin | frop | | alu --> dob | twop |
| (rxa) --> db --> au |--------| | (alub) --> alu |--------|
| -1,-2 --> au | db | | au --> aob | dbi |
| |--------| | (pc) --> db --> au |--------|
C | | x | | -1 --> alu | 1f |
| |--------| | +2 --> au |--------|
| | | | | |
|___________________________|________| |___________________________|________|
| 102 | asxw3 | asxw3 | | 2b7 | mall3 | mall3 |
\------------------------------------/ \------------------------------------/
| |
v v
____________________________________ malw3
| <> m | |
| au --> * --> aob,at,rxa | trop |
| (dbin) --> db* --> alub |--------|
| edb --> dbin | dbi |
| |--------|
D | | x |
| |--------|
| | |
|___________________________|________|
| 212 | asxw4 | asxw4 |
\------------------------------------/
| asxw5
vhttp://nemesis.exodusemulator.com/M6800 ... heet A.pdf
http://nemesis.exodusemulator.com/M6800 ... heet B.pdf
I'll post the full transcription when it's done.
-
HardWareMan
- Very interested
- Posts: 750
- Joined: Sat Dec 15, 2007 7:49 am
- Location: Kazakhstan, Pavlodar
Re: I'm officially building a microcode-level 68000 core
This is just 6NOR logic with those 6 "signals" as boolean variables. I think this is came from xHDL or transistor level schematic. So there no need to label every signal line because of there are thousends of it. Only imported ones must be named and it seems that they are.Nemesis wrote: ↑Sat May 04, 2019 6:06 amThere's also a bit of a fondness for abbreviated variable and function names. Can anyone decipher what this means?Yeah, me neither.Code: Select all
bool n2388 = !(s.clk || s.berro || s.n1361 || s.n2735 || s.n2772 || s.n2781);
Re: I'm officially building a microcode-level 68000 core
I'm going to start write-ups on what I've learned so far, as I've been able to digest and document it. This should serve as a bit of a "microcode 101" introduction to the Motorola 68000 for others, and a reference for me when I inevitably forget half of what I've figured out in a week's time. For a lot of this, I'm treading ground that some other people have already covered, but information that isn't shared is ultimately doomed to have to be re-discovered in the future, and I can't find detailed information on this stuff that anyone's shared before. Hopefully this thread will change that, so other people won't have to go over this same area again.
What is microcode?
When I first looked at this problem back in 2012, I wrote the following:
For the 68000 specifically, there are a few terms I'm going to define before going any further
Microinstruction - A "true" internal instruction that the CPU executes
Macroinstruction - An instruction from the external "programmer's" perspective.
Microcode - The "programmable" data block that defines the microinstructions
Nanocode - Another "programmable" data block that will be discussed below
A microinstruction is effectively a discrete set of work that the processor performs together. A single macroinstruction will execute at least one microinstruction, but it may require several microinstructions to implement a given macroinstruction. The CPU is executing no more than one microinstruction at any given time, with microinstructions executing sequentially. Each microinstruction itself determines which instruction will follow it, with the instructions being able to perform absolute or conditional branches to other microinstructions, or to request the next waiting macroinstruction to determine the microinstruction to follow it. No exceptions can interrupt the execution of a microinstruction, and they will always execute in their entirety, not even a reset signal will prevent them from completing. Exceptions can interrupt the normal flow of microinstructions, with a pending exception potentially overriding the next microinstruction to execute. Microinstructions themselves encode when they are the last instruction in a chain of microinstructions implementing a macroinstruction, allowing exceptions that need to wait for macroinstruction boundaries to take over execution at the correct time. Serious exceptions, such as a bus error, will substitute a new microinstruction to execute as soon as the currently executing microinstruction completes. Microinstructions are not necessarily more generic or fewer in number than macroinstructions, in fact in the case of the 68000 they're greater in number and often more specific.
What is nanocode?
The 68000 contains both "microcode" and "nanocode". If the microcode defines the microinstructions, what does the nanocode define? Effectively, the nanocode also contains part of the definition of the microinstructions. The separation between microcode and nanocode in the 68000 is fairly arbitrary, and is done for space and efficiency reasons. In the 68000, the microcode contains a 17-bit value per microinstruction, which largely relates to the control flow of that microinstruction. This data will inform the processor of which instruction will follow it, or in the case of conditional branching logic, how that branching decision will be made, and which set of possible resulting microinstructions could be executed. The nanocode on the other hand stores a 68-bit value, and its output is used to drive control signals across the various units in the processor, to direct the work to be performed. Effectively the microcode contains the sequencing information for a microinstruction, and the nanocode contains the actual set of steps to perform when executing that microinstrution. This separation in the 68000 allowed the designers to re-use nanocode for multiple microinstructions where the work to perform was the same, and only the sequencing information differs. In the 68000, space was provided for 544 microinstructions in the microcode store, while only 336 entries were required in the nanocode store. It would be possible to unify the microcode and nanocode into a single data structure with 85-bit (17+68) entries, but this would have required an additional 14144 bits of data to be encoded. Avoiding encoding this redundant data saved die space, which would have improved manufacturing yields and reduced the cost per chip.
What authoritative reference material do we we have?
There's a bit of a unique situation with the 68000, in that we have both a thorough decapping and analysis of the physical die surface on the real production CPU, as well as unusually specific, detailed design documentation from Motorola through their patent filings. Both of them are valuable resources. From the decapping work, we have the following primary raw materials:
http://www.visual6502.org/images/pages/ ... 68000.html - Visual6502's decap of the 68000
https://og.kervella.org/m68k/original/ - A different 68000 decap, I'm not sure of the origin of this one. (Did Olivier Galibert pay for it himself?)
There's also some useful interpretation of these die shots:
https://og.kervella.org/m68k/layers.svg - Olivier's generated svg die layout. Here's a pdf version I made which I find is quicker to load and easier to work with.
https://og.kervella.org/m68k/schem.svg - Olivier's generated schematic die layout. Here's a dynamic map version of that.
As for the patents, we have the following of particular note:
US4325121 - Gives a lot of detail on macroinstruction/microinstruction decoding, as well as providing full listings of the microcode, with the operations they perform. Some of the microcode pages are missing, and one is scanned incorrectly. EP0019392B1 has slightly higher resolution scans with the missing content.
Other patents as referenced here. I haven't gone through all them yet, so I'll probably update this list later.
Both of these two sources of information are vital, and we can use them to inform each other. The die shots are very important, as they serve as irrefutable proof of the way the 68000 is actually constructed. We can also, very importantly in this context, read out the individual bits of the microcode and nanocode stores, as well as the decoding logic that addresses into them, and the logic that operates on the output from these arrays. Looking at die shots alone can be hard to interpret though, and while you can get a good understanding of the physical structure of the processor from this kind of work, making progress at this level can be guelling and time consuming, and you can't determine the proper names for a lot of things (IE, internal registers, microinstructions). On the other hand, patents are often written before an invention is complete, and in the case of these patents, we can observe several cases where the macroinstructions have changed from what is listed in the patents to what was implemented in the released processor. We need to use the die shots to identify information from the patents that's no longer accurate, and figure out what the correct information is for the final product.
Where to from here?
My goal is to build a complete listing of all the microinstructions in the production 68000 processor, determine how the macroinstructions map to those microinstructions, and determine the exact steps each microinstruction performs. With that information, I can construct a new 68000 core that fundamentally operates on microinstructions, rather than basing it around macroinstructions like my 68000 core, and all others I know of, currently do. This will allow precise external bus timing to be implemented in a natural way, while also addressing various quirks some opcodes are known to have (IE, this), and also covering other ones we might not know yet.
In order to achieve this goal, I'm starting primarily with the patents, and seeking to absorb all the information in them and understand them fully. Along the way, I'm also comparing what I learn from the patents with what I can see on the die shots, so I can relate the two together. I'll post more information on this in the near future.
Why not go further and fully emulate the 68000 at the transistor level?
It's a good question. If you're already mapping the physical traces on the die and emulating internal aspects of the chip, reproducing all the internal logic directly from the physical layout and emulating it exactly isn't that much further. For some purposes, this is exactly what people want. Work has been done on FPGA implementations of the 68000 core for example. In these cases, you want something you can drop in as an equivalent replacement for the original chip, that performs exactly how it would have done, or possibly even better (IE, higher clock rates). This doesn't suit all purposes though. Looking specifically at software emulation rather than FPGAs and hardware clones, some of the pro's of this approach are as follows:
1. Accuracy. If the die shots have been correctly analyzed, some gotchas and caveats notwithstanding, you can create a known 100% accurate emulation core.
2. Ease of development. Tools exist that'll spit out code from things like netlists and CPU schematics. Theoretically, with a perfect analysis, you can build a CPU core for it rather quickly by feeding the layout information into a code generator.
These advantages are appealing, but they come with some major drawbacks:
1. Transparency. After simply converting a transistor-level schematic directly to an emulation core, it's still a black box. This might suit some purposes just fine, but what if you want your 68000 core to also be able to give you a disassembly? What if you want it to be able to show you the state of internal registers, to name the microinstruction it's currently executing, and generate a trace log of events that have occurred internally? Not all emulators care about these things, but if you want a 68000 core to be more than a black box, into which you feed code and get out bus operations at certain timings, and know nothing more about what's happening in the middle, you're going to need to do a lot of work beyond dropping in some autogenerated code.
2. Performance. General purpose processors for the computers we all know and love are good at doing sequential work at high speed, but they're pretty terrible at doing massively parallel, highly contentous tasks. Internally, CPUs are massively parallel. Even for the 68000, hundreds of control lines could be firing at once, directing areas of the CPU to perform bits of work, all of it with known engineered timing that makes sure that things get sequenced in the right order. Emulating that in code is thousands of operations, and a lot of conditional logic, much of it with terrible branch predictability, and all of it occurring sequentially rather than in parallel.
I think in reality having both of these approaches fully done is very valuable. A 100% accurate reference core generated from schematics would be a fantastic resource, as it can be used to validate behaviour in other manually constructed cores. Likewise, a manually constructed core necessitates a level of deep analysis and (hopefully) thorough documentation, which can help others understand and put into context the operations that are being performed within an autogenerated reference core, as well as enabling powerful inspection and debugging features.
I'll leave things there for now. Sometime soon I'll make another post with what I've learned about how microinstructions are encoded, stored and addressed based on the patent descriptions, and show how that information links back to the physical connections on the die. In that process I'll demonstrate how to visually read out the microcode and nanocode stores by looking at the die shots, and how that data maps to the structure given in the patents.
What is microcode?
When I first looked at this problem back in 2012, I wrote the following:
This is a fairly good summary of what it means for a processor to be microcoded. A microcoded processor is one that has an internal set of programmable instructions, which is separate and distinct from the external set of instructions that the programmer can see. The term "programmable instructions" is important here, as a processor is only truly considered to be "microcoded" if the internal instructions are reconfigurable by altering internal data tables, which in the case of the 68000 are encoded in the form of PLAs (which I'll cover later). The main goal of microinstructions is really to simplify the design and production of the processor.Nemesis wrote:The M68000 is microcoded, meaning every single machine code instruction the CPU reads isn't really an instruction for the CPU directly, it's more like a key, telling it what set of internal instructions to execute. In a way, microcode is kind of like a data table the CPU uses internally to map these high-level "macro" instructions down to a set of real-low level internal operations to execute. A single opcode for example may actually be made up of a dozen internal operations, or internal execution steps.
For the 68000 specifically, there are a few terms I'm going to define before going any further
Microinstruction - A "true" internal instruction that the CPU executes
Macroinstruction - An instruction from the external "programmer's" perspective.
Microcode - The "programmable" data block that defines the microinstructions
Nanocode - Another "programmable" data block that will be discussed below
A microinstruction is effectively a discrete set of work that the processor performs together. A single macroinstruction will execute at least one microinstruction, but it may require several microinstructions to implement a given macroinstruction. The CPU is executing no more than one microinstruction at any given time, with microinstructions executing sequentially. Each microinstruction itself determines which instruction will follow it, with the instructions being able to perform absolute or conditional branches to other microinstructions, or to request the next waiting macroinstruction to determine the microinstruction to follow it. No exceptions can interrupt the execution of a microinstruction, and they will always execute in their entirety, not even a reset signal will prevent them from completing. Exceptions can interrupt the normal flow of microinstructions, with a pending exception potentially overriding the next microinstruction to execute. Microinstructions themselves encode when they are the last instruction in a chain of microinstructions implementing a macroinstruction, allowing exceptions that need to wait for macroinstruction boundaries to take over execution at the correct time. Serious exceptions, such as a bus error, will substitute a new microinstruction to execute as soon as the currently executing microinstruction completes. Microinstructions are not necessarily more generic or fewer in number than macroinstructions, in fact in the case of the 68000 they're greater in number and often more specific.
What is nanocode?
The 68000 contains both "microcode" and "nanocode". If the microcode defines the microinstructions, what does the nanocode define? Effectively, the nanocode also contains part of the definition of the microinstructions. The separation between microcode and nanocode in the 68000 is fairly arbitrary, and is done for space and efficiency reasons. In the 68000, the microcode contains a 17-bit value per microinstruction, which largely relates to the control flow of that microinstruction. This data will inform the processor of which instruction will follow it, or in the case of conditional branching logic, how that branching decision will be made, and which set of possible resulting microinstructions could be executed. The nanocode on the other hand stores a 68-bit value, and its output is used to drive control signals across the various units in the processor, to direct the work to be performed. Effectively the microcode contains the sequencing information for a microinstruction, and the nanocode contains the actual set of steps to perform when executing that microinstrution. This separation in the 68000 allowed the designers to re-use nanocode for multiple microinstructions where the work to perform was the same, and only the sequencing information differs. In the 68000, space was provided for 544 microinstructions in the microcode store, while only 336 entries were required in the nanocode store. It would be possible to unify the microcode and nanocode into a single data structure with 85-bit (17+68) entries, but this would have required an additional 14144 bits of data to be encoded. Avoiding encoding this redundant data saved die space, which would have improved manufacturing yields and reduced the cost per chip.
What authoritative reference material do we we have?
There's a bit of a unique situation with the 68000, in that we have both a thorough decapping and analysis of the physical die surface on the real production CPU, as well as unusually specific, detailed design documentation from Motorola through their patent filings. Both of them are valuable resources. From the decapping work, we have the following primary raw materials:
http://www.visual6502.org/images/pages/ ... 68000.html - Visual6502's decap of the 68000
https://og.kervella.org/m68k/original/ - A different 68000 decap, I'm not sure of the origin of this one. (Did Olivier Galibert pay for it himself?)
There's also some useful interpretation of these die shots:
https://og.kervella.org/m68k/layers.svg - Olivier's generated svg die layout. Here's a pdf version I made which I find is quicker to load and easier to work with.
{kind=link}
https://og.kervella.org/m68k/schem.svg - Olivier's generated schematic die layout. Here's a dynamic map version of that.
{kind=link}
As for the patents, we have the following of particular note:
US4325121 - Gives a lot of detail on macroinstruction/microinstruction decoding, as well as providing full listings of the microcode, with the operations they perform. Some of the microcode pages are missing, and one is scanned incorrectly. EP0019392B1 has slightly higher resolution scans with the missing content.
Other patents as referenced here. I haven't gone through all them yet, so I'll probably update this list later.
Both of these two sources of information are vital, and we can use them to inform each other. The die shots are very important, as they serve as irrefutable proof of the way the 68000 is actually constructed. We can also, very importantly in this context, read out the individual bits of the microcode and nanocode stores, as well as the decoding logic that addresses into them, and the logic that operates on the output from these arrays. Looking at die shots alone can be hard to interpret though, and while you can get a good understanding of the physical structure of the processor from this kind of work, making progress at this level can be guelling and time consuming, and you can't determine the proper names for a lot of things (IE, internal registers, microinstructions). On the other hand, patents are often written before an invention is complete, and in the case of these patents, we can observe several cases where the macroinstructions have changed from what is listed in the patents to what was implemented in the released processor. We need to use the die shots to identify information from the patents that's no longer accurate, and figure out what the correct information is for the final product.
Where to from here?
My goal is to build a complete listing of all the microinstructions in the production 68000 processor, determine how the macroinstructions map to those microinstructions, and determine the exact steps each microinstruction performs. With that information, I can construct a new 68000 core that fundamentally operates on microinstructions, rather than basing it around macroinstructions like my 68000 core, and all others I know of, currently do. This will allow precise external bus timing to be implemented in a natural way, while also addressing various quirks some opcodes are known to have (IE, this), and also covering other ones we might not know yet.
In order to achieve this goal, I'm starting primarily with the patents, and seeking to absorb all the information in them and understand them fully. Along the way, I'm also comparing what I learn from the patents with what I can see on the die shots, so I can relate the two together. I'll post more information on this in the near future.
Why not go further and fully emulate the 68000 at the transistor level?
It's a good question. If you're already mapping the physical traces on the die and emulating internal aspects of the chip, reproducing all the internal logic directly from the physical layout and emulating it exactly isn't that much further. For some purposes, this is exactly what people want. Work has been done on FPGA implementations of the 68000 core for example. In these cases, you want something you can drop in as an equivalent replacement for the original chip, that performs exactly how it would have done, or possibly even better (IE, higher clock rates). This doesn't suit all purposes though. Looking specifically at software emulation rather than FPGAs and hardware clones, some of the pro's of this approach are as follows:
1. Accuracy. If the die shots have been correctly analyzed, some gotchas and caveats notwithstanding, you can create a known 100% accurate emulation core.
2. Ease of development. Tools exist that'll spit out code from things like netlists and CPU schematics. Theoretically, with a perfect analysis, you can build a CPU core for it rather quickly by feeding the layout information into a code generator.
These advantages are appealing, but they come with some major drawbacks:
1. Transparency. After simply converting a transistor-level schematic directly to an emulation core, it's still a black box. This might suit some purposes just fine, but what if you want your 68000 core to also be able to give you a disassembly? What if you want it to be able to show you the state of internal registers, to name the microinstruction it's currently executing, and generate a trace log of events that have occurred internally? Not all emulators care about these things, but if you want a 68000 core to be more than a black box, into which you feed code and get out bus operations at certain timings, and know nothing more about what's happening in the middle, you're going to need to do a lot of work beyond dropping in some autogenerated code.
2. Performance. General purpose processors for the computers we all know and love are good at doing sequential work at high speed, but they're pretty terrible at doing massively parallel, highly contentous tasks. Internally, CPUs are massively parallel. Even for the 68000, hundreds of control lines could be firing at once, directing areas of the CPU to perform bits of work, all of it with known engineered timing that makes sure that things get sequenced in the right order. Emulating that in code is thousands of operations, and a lot of conditional logic, much of it with terrible branch predictability, and all of it occurring sequentially rather than in parallel.
I think in reality having both of these approaches fully done is very valuable. A 100% accurate reference core generated from schematics would be a fantastic resource, as it can be used to validate behaviour in other manually constructed cores. Likewise, a manually constructed core necessitates a level of deep analysis and (hopefully) thorough documentation, which can help others understand and put into context the operations that are being performed within an autogenerated reference core, as well as enabling powerful inspection and debugging features.
I'll leave things there for now. Sometime soon I'll make another post with what I've learned about how microinstructions are encoded, stored and addressed based on the patent descriptions, and show how that information links back to the physical connections on the die. In that process I'll demonstrate how to visually read out the microcode and nanocode stores by looking at the die shots, and how that data maps to the structure given in the patents.
Re: I'm officially building a microcode-level 68000 core
Impressive work nemesis i will read all your documentation with much interest !
-
HardWareMan
- Very interested
- Posts: 750
- Joined: Sat Dec 15, 2007 7:49 am
- Location: Kazakhstan, Pavlodar
Re: I'm officially building a microcode-level 68000 core
Also I think we should make cycle and logic accurate 68000 model for FPGA.
Re: I'm officially building a microcode-level 68000 core
Great write up Nemesis, thanks! I look forward to the next one.
Over the past week I've been pouring over the netlist on Oliver's website trying to wrap my head around how this stuff works. I found some discrepancies between his schem.txt and schem.svg, emailed him to ask if indeed there was something strange going on or if it was just my lack of understanding, and he was kind enough to regenerate both of them for me saying they were out of date. So if you've been diving in to those files like I have, grab the new ones!
Re: I'm officially building a microcode-level 68000 core
Hi Nemesis,
 But see my comments below.
But see my comments below.
Look at this die shot: http://www.easy68k.com/paulrsm/doc/dpbm68k2.htm
There is a huge PLA labeled IRD BUS in the floorplan between the microcode and the actual execution unit control. No sure who labeled it as a bus, but that is misleading, it is a PLA, not a bus. And it is huge, this is not just a simple decoding of the nanorom. This has a lot of hardcoded functionality that is missing at all at the microcode. I actually must confess that this was quite a disappointment when I found out. It means that the microcode and the whole design of the 68K are not as efficient as I previously thought.
Just as an example off the top of my head:
The microcode is supposed to describe register transfers. This is perhaps the main purpose of the nanocode. But it doesn't always specify exactly which type of registers are transferred. I.e., it doesn't specify if "RX" and "RY" are address or data registers (even in those cases that is seems to be specified at the patent, that information is not actually at the microcode); or if RX is actually the temporary register, the USP, or actually from a MOVEM register list.
In a nutshell. Correct microcode level emulation would probably grant you accurate bus access order, especially the (seemingly) weird order of pushing the exception stack frame. Timing would also be very accurate, of course, but not necessarily 100% exact.
It is not at all my intention to discourage you to implement microcode level emulation. Quite the contrary, again, it would be great. And besides, I think that studying the microcode is fascinating Just trying to mention the possible limitations of what microcode emulation could possibly mean.
This doesn't have much to do with the microcode. Yes, ABCD and SBCD use the same microcode. But the exact undocumented behavior of the flags at the BCD instructions has (almost) nothing to do with the microcode at all.
Btw, this undocumented behavior was solved many years ago, not at all by myself, but even long before I started my reverse engineering research. I think I still have the original document that describes the exact procedure to compute the flags. But I'm afraid I'm not sure I have the reference to where I got the document, or who was the author to give proper credit.
I think this is just a so great idea and I definitely look forward for your results
Not just many but all of them. Otherwise the core wouldn't work, or at least it wouldn't work correctly.ijor's verilog implementation of the 68000 based on decap. Has many of the internal control lines from the nanocode output identified in particular.
They are not just barely readable, be aware they have quite some errors and typos. Remember that this is not an automatic output of some kind of compiler. Amazing as it might seem, it was mostly a purely manual work. I'm afraid I didn't take notes of all the errors I found, and likely there are others that I didn't find. For quite some time I am concentrating on the actual die, and not on the patent, so I don't even have this very fresh.A lot of important information is contained in the microword descriptions in Appendix H, but they're borderline illegible, and very difficult to work with in their current form,
I think a microcode based emulation is great. But I'm not sure it is strictly necessary for the purpose of cycle accurate emulation. And certainly it is not enough. The microcode doesn't really have full absolute control of the execution as you might think, or as myself thought at one time. As soon as you start studying the microcode you realize that there is lot of stuff that is missing.I can construct a new 68000 core that fundamentally operates on microinstructions, rather than basing it around macroinstructions like my 68000 core, and all others I know of, currently do. This will allow precise external bus timing to be implemented in a natural way, while also addressing various quirks some opcodes are known to have (IE, this), and also covering other ones we might not know yet.
Look at this die shot: http://www.easy68k.com/paulrsm/doc/dpbm68k2.htm
There is a huge PLA labeled IRD BUS in the floorplan between the microcode and the actual execution unit control. No sure who labeled it as a bus, but that is misleading, it is a PLA, not a bus. And it is huge, this is not just a simple decoding of the nanorom. This has a lot of hardcoded functionality that is missing at all at the microcode. I actually must confess that this was quite a disappointment when I found out. It means that the microcode and the whole design of the 68K are not as efficient as I previously thought.
Just as an example off the top of my head:
The microcode is supposed to describe register transfers. This is perhaps the main purpose of the nanocode. But it doesn't always specify exactly which type of registers are transferred. I.e., it doesn't specify if "RX" and "RY" are address or data registers (even in those cases that is seems to be specified at the patent, that information is not actually at the microcode); or if RX is actually the temporary register, the USP, or actually from a MOVEM register list.
In a nutshell. Correct microcode level emulation would probably grant you accurate bus access order, especially the (seemingly) weird order of pushing the exception stack frame. Timing would also be very accurate, of course, but not necessarily 100% exact.
It is not at all my intention to discourage you to implement microcode level emulation. Quite the contrary, again, it would be great. And besides, I think that studying the microcode is fascinating
(Re: undocumented behavior of the BCD instructions)... while also addressing various quirks some opcodes are known to have (IE, this)
This doesn't have much to do with the microcode. Yes, ABCD and SBCD use the same microcode. But the exact undocumented behavior of the flags at the BCD instructions has (almost) nothing to do with the microcode at all.
Btw, this undocumented behavior was solved many years ago, not at all by myself, but even long before I started my reverse engineering research. I think I still have the original document that describes the exact procedure to compute the flags. But I'm afraid I'm not sure I have the reference to where I got the document, or who was the author to give proper credit.
I published a cycle accurate 68K FPGA core about half a year ago. See my signature. There are already some Genesis FPGA cores using it.HardWareMan wrote: ↑Sat May 11, 2019 5:11 amAlso I think we should make cycle and logic accurate 68000 model for FPGA.
http://github.com/ijor/fx68k (68000 cycle accurate FPGA core)
Re: I'm officially building a microcode-level 68000 core
Awesome, thanks! Reaching out to Olivier has been on my to-do list, as I had a whole stack of questions for him. Thanks for getting the ball rolling, an updated schematic will be very helpful. This is actually very timely too, as over the last few days I've cobbled together this:stinkz wrote: ↑Tue May 14, 2019 3:02 amGreat write up Nemesis, thanks! I look forward to the next one.
Over the past week I've been pouring over the netlist on Oliver's website trying to wrap my head around how this stuff works. I found some discrepancies between his schem.txt and schem.svg, emailed him to ask if indeed there was something strange going on or if it was just my lack of understanding, and he was kind enough to regenerate both of them for me saying they were out of date. So if you've been diving in to those files like I have, grab the new ones!
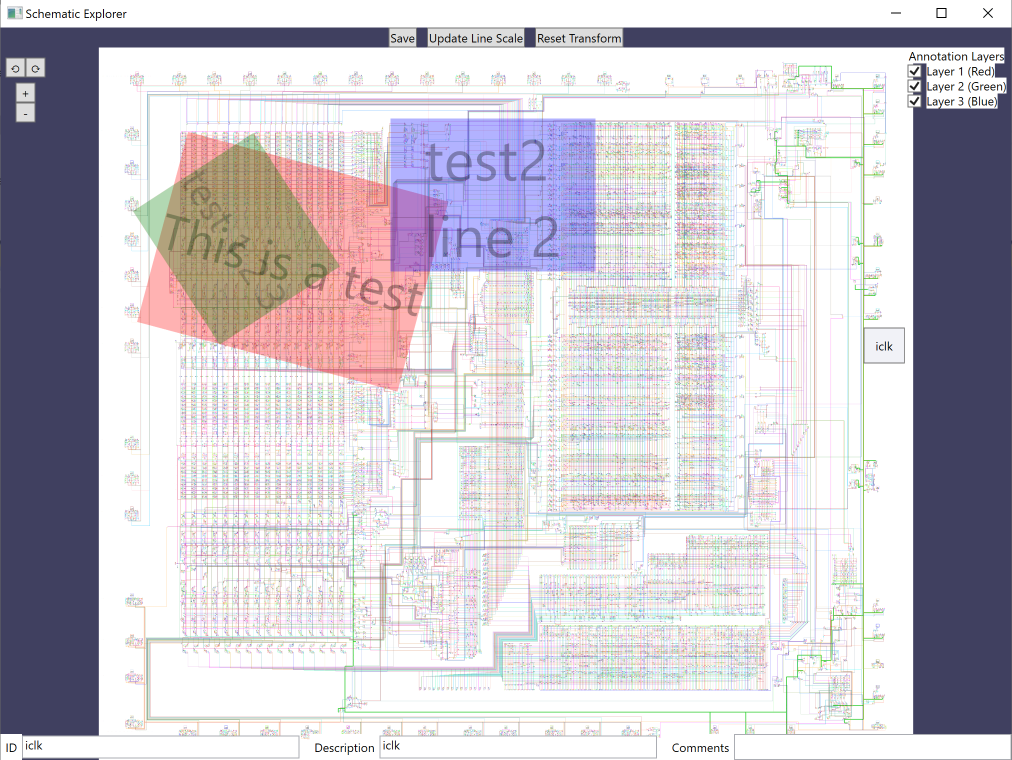
Please excuse the crudity of this model. I didn't have time to build it to scale or paint it. The schematic was incredible, but I found it very hard to work with. Most tools struggled to even open an svg that large, and it was slow and difficult to follow traces with so many of them all in black. I wrote this program, dubbed "Schematic Explorer", which can directly load in the schematic svg, and allow you to rotate and zoom in easily, while also throwing in color, tooltips, dynamic highlighting of lines on mouse-over, and the ability to add custom comments and "annotation" overlays to document the layout, which gets saved to an external xml file along side the schematic. I threw this tool together in C# + WPF, because I know those environments well, and what else can you build something like this in with around 1000 lines of code? There are some things that suck. I wanted the line widths to dynamically adjust when you zoom in our out, but that's rediculously slow, so I've made it a manual process. Press a button (and wait 20 seconds) to recalculate them based on the current zoom level. Navigation is bearable, but still slower than I'd like. Barring doing manual drawing and picking for all of it in OpenGL or Direct3D (which would be 10x the code minimum), it's not going to get any better though.
Here's Olivier's schematic (updated): https://og.kervella.org/m68k/schem.svg
Here's the compiled program: http://nemesis.exodusemulator.com/M6800 ... rerV1.2.7z
And here's the source: http://nemesis.exodusemulator.com/M6800 ... V1.2Src.7z
I'll put the source up on github or something later. You'll need a Windows box with .NET 4.5.2 (Windows Vista or higher) to run the program, which should be already installed. In the unusual case it's not, you can get it from here.
The interface is bare bones. Here's what you need to know:
-Zoom in with the mouse scroll wheel or the +/- buttons
-Rotate the schematic by using the rotate buttons
-Pan by clicking on the background and dragging
-Draw an annotation box by holding ctrl, then clicking and dragging.
-Highlight a trace by moving the mouse over it
-"Lock" a trace (so you can type comments or move while keeping selection) by clicking on it
-Edit an annotation by holding ctrl and clicking on it. "Grabbers" will appear for sizing, moving, and rotating.
-Type a name or comments for an annotation while it's in edit mode
I haven't had a chance to go back and start adding "real" comments to the schematic yet, but with the external annotation file it's easy to share and merge efforts, so if anyone wants to dive in and start identifying areas of the die (IE, "Register D0.h"), or even adding detailed notes on particular lines, give this tool a try and let me know what you think.
Edit: Updated Schematic Explorer
Last edited by Nemesis on Wed May 15, 2019 4:34 am, edited 2 times in total.
Re: I'm officially building a microcode-level 68000 core
Hey ijor, thanks for contributing. I'll have about 1000 questions for you I'm sure, so don't go anywhere!
Right now I'm still at the research phase though. I primarily want to determine how to prove what actions occur from each individual microinstruction, so that I can verify the correct behaviour for each of them. Secondly, but still very importantly, I also want to relate back everything to the patents from Motorola, so where it can be determined, I'm using the same names for things like particular microinstructions and internal registers as the engineers at Motorola did. I want to document everything along the way here though, so that other people can verify my work and use the information to help with other projects.
I'm sure there are a ton of errors. I'm going to start with direct transcriptions, but we could type up some kind of official "errata" to accompany it. I'm not sure if we need to go this far though to be honest. I mostly want to have enough done to easily relate patent microcode information back to what we can derive from the die. We already know there are changes to the microcode for the final released processor anyway, so differences are expected anyway, even without errors.They are not just barely readable, be aware they have quite some errors and typos. Remember that this is not an automatic output of some kind of compiler. Amazing as it might seem, it was mostly a purely manual work. I'm afraid I didn't take notes of all the errors I found, and likely there are others that I didn't find. For quite some time I am concentrating on the actual die, and not on the patent, so I don't even have this very fresh.A lot of important information is contained in the microword descriptions in Appendix H, but they're borderline illegible, and very difficult to work with in their current form,
Thanks for your insights on this. Fortunately, for a software emulation core, I don't necessarily have to worry about what happens past initial microcode decoding, as I'm effectively "high level emulating" the microinstructions, by writing specific code to handle each one. A current "macrocode" level 68000 core for example will have specific code written for individual macroinstructions, such as rts, mov, add, etc. I'll be emulating the macroinstruction decoding logic to determine the first microinstruction, but when it comes to emulating individual microinstructions, I can then rely on manually written code to implement the behaviour. This makes my task a lot simpler than what you've already accomplished as I see it, because while I want to fully understand the steps the CPU takes when executing a microinstruction, and I need in particular to be able to prove the correct behaviour from what we can observe from the die shots and generated schematics (and your FPGA core), after that there's no need for me to fully emulate all the internal execution steps, I can just write some C++ code to perform the work for each microinstruction. I'm still free to share functions at this level to implement common or shared behaviour that's used across microinstructions where it's sensible to do so, but at the end of the day I can make any microinstruction behave any way I want to, and I don't have to worry about being able to directly load in the microcode data to define instructions, or decode PLA structures to determine how things operate.I think a microcode based emulation is great. But I'm not sure it is strictly necessary for the purpose of cycle accurate emulation. And certainly it is not enough. The microcode doesn't really have full absolute control of the execution as you might think, or as myself thought at one time. As soon as you start studying the microcode you realize that there is lot of stuff that is missing.I can construct a new 68000 core that fundamentally operates on microinstructions, rather than basing it around macroinstructions like my 68000 core, and all others I know of, currently do. This will allow precise external bus timing to be implemented in a natural way, while also addressing various quirks some opcodes are known to have (IE, this), and also covering other ones we might not know yet.
Look at this die shot: http://www.easy68k.com/paulrsm/doc/dpbm68k2.htm
There is a huge PLA labeled IRD BUS in the floorplan between the microcode and the actual execution unit control. No sure who labeled it as a bus, but that is misleading, it is a PLA, not a bus. And it is huge, this is not just a simple decoding of the nanorom. This has a lot of hardcoded functionality that is missing at all at the microcode. I actually must confess that this was quite a disappointment when I found out. It means that the microcode and the whole design of the 68K are not as efficient as I previously thought.
Just as an example off the top of my head:
The microcode is supposed to describe register transfers. This is perhaps the main purpose of the nanocode. But it doesn't always specify exactly which type of registers are transferred. I.e., it doesn't specify if "RX" and "RY" are address or data registers (even in those cases that is seems to be specified at the patent, that information is not actually at the microcode); or if RX is actually the temporary register, the USP, or actually from a MOVEM register list.
In a nutshell. Correct microcode level emulation would probably grant you accurate bus access order, especially the (seemingly) weird order of pushing the exception stack frame. Timing would also be very accurate, of course, but not necessarily 100% exact.
Right now I'm still at the research phase though. I primarily want to determine how to prove what actions occur from each individual microinstruction, so that I can verify the correct behaviour for each of them. Secondly, but still very importantly, I also want to relate back everything to the patents from Motorola, so where it can be determined, I'm using the same names for things like particular microinstructions and internal registers as the engineers at Motorola did. I want to document everything along the way here though, so that other people can verify my work and use the information to help with other projects.
Re: I'm officially building a microcode-level 68000 core
I've just updated the schematic explorer to fix some transformation issues, as well as improve the speed for updating the line scaling. If anyone's downloaded the previous build, I'd recommend moving to the updated one.